大数据开发软件安装篇之Linux操作系统——图文详解与系统软件定制开发
在当今数据驱动的时代,大数据开发已成为众多企业和研究机构的核心任务。作为大数据生态的基础,Linux操作系统因其稳定性、高效性和开源特性,成为大数据开发的首选平台。本文将结合图文详细讲解Linux操作系统的安装、系统软件定制开发,帮助初学者和开发者快速上手大数据环境搭建。
一、Linux操作系统简介与选择
Linux是一种自由和开放源代码的类Unix操作系统,广泛应用于服务器、嵌入式设备和大数据平台。常见发行版包括Ubuntu、CentOS、Red Hat等,其中CentOS因其稳定性和企业级支持,在大数据领域尤为流行。
二、Linux系统安装图文详解
1. 准备工作
- 下载ISO镜像:从官方网站(如centos.org)下载最新版本的CentOS镜像文件。
- 制作启动盘:使用工具如Rufus或Etcher将ISO文件写入U盘,制作启动盘。
- 硬件检查:确保计算机满足最低配置要求(如2GB内存、20GB硬盘空间)。
2. 安装步骤(以CentOS 7为例)
- 启动安装:插入U盘,重启计算机,进入BIOS设置从U盘启动。
- 选择语言:在安装界面选择中文或英文作为系统语言。
- 磁盘分区:选择自动分区或手动分区(推荐手动,如分配/boot、swap、/根目录)。
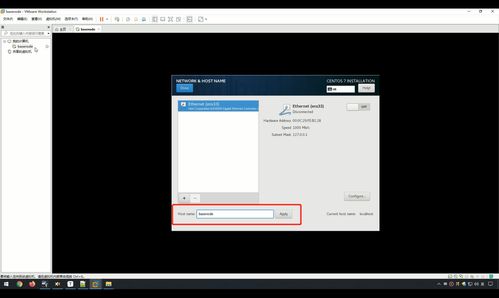
- 网络配置:设置主机名、IP地址(建议使用静态IP以便后续大数据软件配置)。
- 用户设置:创建root密码和普通用户账户。
- 开始安装:确认设置后,系统将自动安装,完成后重启。
(图文示例:此处可插入安装界面截图,如分区设置、网络配置界面)
三、系统软件定制开发
大数据开发往往需要定制系统环境,包括安装依赖软件、配置网络和安全设置。以下为关键步骤:
1. 基础软件安装
- 更新系统:使用
yum update命令更新系统包。 - 安装开发工具:通过
yum groupinstall 'Development Tools'安装GCC、Make等编译工具。 - 安装Java:大数据框架如Hadoop依赖Java,可使用
yum install java-1.8.0-openjdk安装。
2. 大数据环境配置
- SSH无密码登录:配置SSH密钥以实现集群节点间无密码访问,命令示例:
`bash
ssh-keygen -t rsa
ssh-copy-id user@hostname
`
- 时间同步:使用NTP服务确保集群时间一致,命令:
yum install ntp && systemctl start ntpd。 - 防火墙配置:开放大数据软件所需端口,如Hadoop的50070端口。
3. 定制化脚本开发
为简化重复操作,可编写Shell脚本自动化安装和配置。例如,创建一个脚本自动安装Hadoop:`bash
#!/bin/bash
下载Hadoop
wget http://apache.org/hadoop-3.3.0.tar.gz
# 解压并配置环境变量
tar -xzf hadoop-3.3.0.tar.gz
echo 'export HADOOP_HOME=/path/to/hadoop' >> ~/.bashrc`
四、总结与注意事项
Linux系统的正确安装和定制是大数据开发的基础。在实际操作中,需注意:
- 确保硬件兼容性和网络稳定性。
- 定期备份系统配置,避免数据丢失。
- 参考官方文档和社区资源解决常见问题。
通过本文的图文详解和定制开发指南,读者可快速搭建稳定的大数据开发环境,为后续的Hadoop、Spark等框架部署奠定基础。如有疑问,欢迎在评论区交流!
如若转载,请注明出处:http://www.haoxiangzhuankj.com/product/705.html
更新时间:2025-10-26 05:30:01